What is Clustering? | Clustering in Machine Learning
May 6, 2023
Dec 31, 2025
Written by: Amirhossein Komeili
Reviewed by: Boshra Rajaei, PhD
Written by: Amirhossein Komeili
Reviewed by: Boshra Rajaei, PhD
In general, clustering in machine learning process helps to organize the data into different structures so that the organization's data can be understood. In fact, when big data is included in the work process, clustering can help us a lot, so clustering, in addition to helping with data structure, can lead to better business decisions.
The process of clustering in machine learning is such that different types of data are grouped together. As a result, it becomes easier to organize data that has different factors and parameters. It is better to know that clustering has different types and techniques that lead to faster and easier work. Stay with us till the end of the article to learn more about clustering.
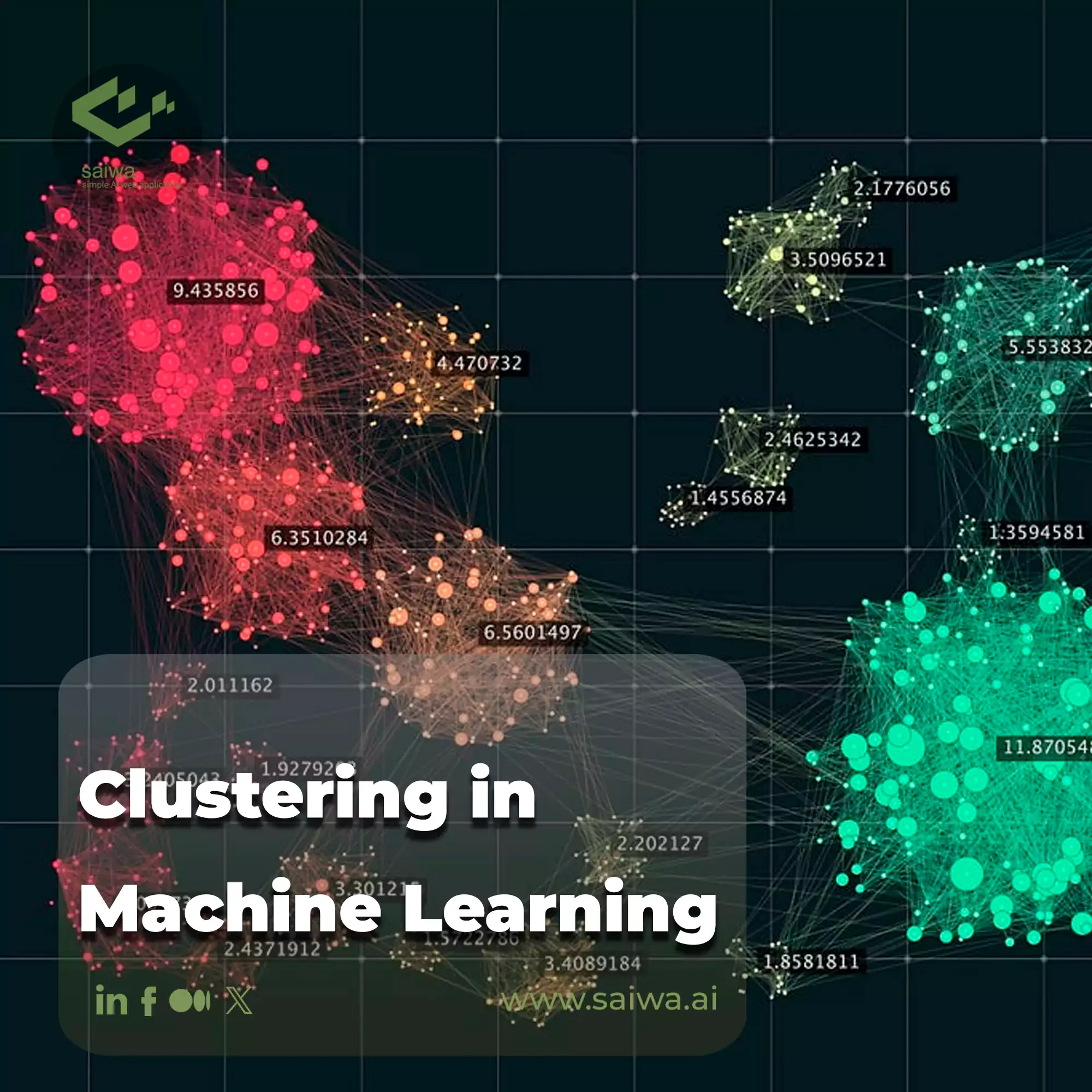
In AI, a cluster is a group or collection of data points or instances that share similar characteristics or exhibit patterns of similarity. The similarity can be based on various attributes, characteristics, or measurements of the data points. The main idea behind clustering is to group data points that are more similar than data points in other clusters. Clusters can represent meaningful subsets or subgroups within a larger data set, providing insight into the underlying structure of the data.
Clustering is the process of grouping data points into clusters based on their inherent patterns or similarities without prior knowledge of class labels or categories. It is an unsupervised learning technique used in machine learning and data mining. Clustering algorithms aim to divide a dataset into subsets, or clusters, where data points within the same cluster are more similar than those in different clusters. Clustering can help identify groups of customers with similar purchasing behavior, group images based on their visual characteristics, identify anomalies or outliers in data, or segment documents based on their content.
To make this easier to understand, let us give you an example. Imagine you are a salesperson and want to pay more attention to your customers' preferences to increase your profit and revenue. Can you consider the details of each person individually and use a unique strategy for each person? The answer is no. But the better solution you can choose is to group your customers based on their habits and preferences and choose a unique strategy for each group. The result of this process is called clustering.

Clustering or cluster analysis is a machine learning technique that groups a set of unlabeled data. Clustering in machine learning method can be used to group data with similar points. In fact, in this method, data that have possible similarities remain in a group. This process is done by finding similar patterns in unlabeled data, such as shape, size, color, behavior, and other factors. Clustering is an unsupervised learning method, so there is no supervision for the algorithm. After clustering, a cluster ID is considered for each cluster. The MLaaS system can use this option to facilitate the processing of large and complex data sets.
Clustering has several algorithms that result in the management of unique data types. The following describes some of the clustering algorithms.
This type of clustering groups data based on the concentration of points. The method relies on density in such a way that it finds the area where the data points are dense and considers it a cluster. Clusters can be of any shape, and there is no limit to the number of expected clusters. This method works in such a way that outliers are not assigned to clusters and are ignored.
In this approach, all data points are considered based on their membership in a cluster. That is, there is one point as the center, and as the data distance from the center increases, the probability that it is part of this cluster decreases. If you choose this method, but you are not sure how to distribute your data, it is better to choose another type of method.
You have probably heard of this method before. This method is a bit sensitive to the initial parameters you give it, but it does the job quickly and efficiently. This method separates data points based on multiple centers in the data. Each point is assigned to a cluster based on the square of its distance from the center. This method is one of the most widely used types of clustering in machine learning.
This method is usually used for hierarchical data. In effect, the data is organized in the form of a tree from top to bottom. This type of method is more limited than other clustering methods, but it is excellent for certain types of data.

Clustering is a fundamental unsupervised learning technique in machine learning that groups similar data points together. It is a powerful tool for exploring and understanding complex data structure, identifying patterns, and extracting insights. Here's how to perform clustering in machine learning:
The first step is the preparation of your data for clustering. This step includes handling missing values, scaling or normalizing features, and performing any necessary data transformations to ensure that your data is in a format suitable for the clustering algorithm.
If you have a high-dimensional dataset, it may be beneficial to perform feature selection or dimensionality reduction techniques to reduce the number of features and improve clustering performance.
Choose an appropriate clustering algorithm based on your data and problem. Some commonly used algorithms include k-means, hierarchical clustering, DBSCAN, Gaussian mixture models, and density-based algorithms.
Depending on the selected clustering algorithm, there may be hyperparameters that need to be set. These parameters control the behavior of the algorithm, such as the number of clusters (k) for k-means or the minimum number of points for DBSCAN.
Apply the selected algorithm to cluster the data. The algorithm assigns each data point to a specific cluster based on the similarity or distance metric used.
Evaluate the quality and validity of the clustering results. Cluster evaluation metrics can vary depending on the nature of the data and the objectives of the clustering.
analyze and interpret the clustering results to gain insight into the underlying structure of the data. Visualization techniques such as scatterplots, heatmaps, or dendrograms can be used to visually explore the clusters and understand their characteristics.

In this section, we will discuss some of the most important and well-known applications of clustering in machine learning.
Clustering in machine learning is widely used to identify cancer cells. In fact, clustering is divided into cancerous and non-cancerous data sets.
Search engines also use clustering in machine learning techniques. In fact, the search result appears based on the closest option to the searched term. This process is done in the form of grouping similar and dissimilar data. In order to determine the exact result of the search, one should pay attention to the quality of the clustering algorithm used.
In research conducted in different markets, clustering is used to divide customers based on their choices and preferences.
In biology, they use clustering techniques such as image recognition to classify different types of plants and animals.
Clustering in Machine Learning technique is used to identify the user area in GIS databases. By using this technique, we can understand what the land in question should be used for and what it is useful for us.

Clustering in machine learning comes with several challenges that practitioners need to be aware of. Here are some common challenges associated with clustering:
Clusters may change over time due to data changes
In cluster analysis, it is difficult to examine and handle outlier data
Clustering techniques struggle with datasets that have high dimensions
It is possible to have several correct answers to a problem
Correct evaluation of solutions is problematic
Clustering calculations can be complex and even expensive
There is a struggle with lost data
Note: Some visuals on this blog post were generated using AI tools.
