Computer vision, a field focused on enabling computers to "see" and interpret images much like humans do, has seen remarkable progress in recent years, largely due to the rise of deep learning. Within this field, autoencoders have emerged as a powerful class of neural networks that have shown significant potential in various computer vision tasks. By their essential nature, autoencoders learn compressed representations of input data, effectively capturing the underlying structure and features. This capability makes them highly versatile tools for applications such as anomaly detection, image denoising, image generation, image classification, segmentation, and super-resolution.
Saiwa provides specialized artificial intelligence (AI) solutions through its Fraime Platform, which offers AI-as-a-Service and machine learning services customized for sectors such as agriculture and manufacturing.
Among the services offered is Saiwa's anomaly detection solution, which employs autoencoders, notably UNet and ResNet34-FPN networks, for highly precise detection in visual data. These advanced networks facilitate the efficient detection of anomalies by businesses, thereby optimizing processes and enhancing outcomes across a range of applications.
This article explores the intricacies of autoencoders, delving into their architecture, various types, applications in computer vision, advantages, limitations, and future prospects.

What is an Autoencoder?

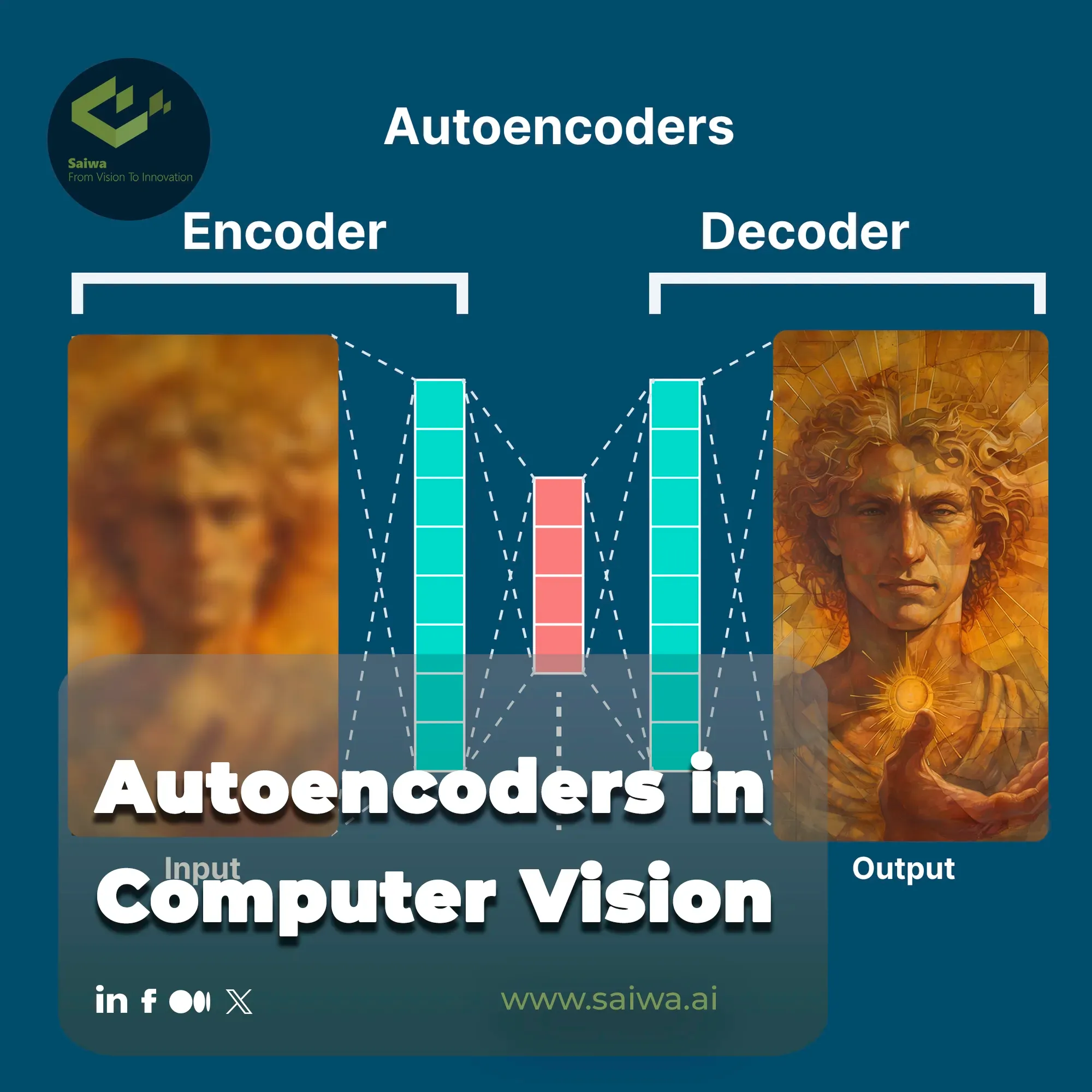
An autoencoder is a type of artificial neural network designed specifically for unsupervised learning of efficient data coding. It works by attempting to learn a representation (encoding) for a set of data, typically for dimensionality reduction, by training the network to ignore signal “noise.” In essence, it learns a compressed representation of the input data, and then reconstructs the input from this representation.
This process involves two main components: an encoder, which maps the input data into a lower-dimensional latent space, and a decoder, which maps the latent representation back into the original input space. The learning process is driven by minimizing the difference between the original input and the reconstructed output. This forces the autoencoder to capture the most salient features of the input data in its latent representation.
Step-by-Step Process of Autoencoders
The operation of an autoencoder can be broken down into the following key steps:
Input Image
The initial step involves feeding an input image into the autoencoder. This image, which can be grayscale or color, serves as the raw data that the autoencoder will process. The dimensions of the image are determined by the specific application and the architecture of the autoencoder, influencing the subsequent encoding and decoding processes.
The input image can represent various objects, scenes, or patterns, and the autoencoder's task is to learn a compressed representation that captures the essential information within the image.
Encoding
The input image is then passed through the encoder, a neural network designed to compress the image into a lower-dimensional representation. This process, known as encoding, extracts the most important features from the image, discarding irrelevant information. The encoder effectively transforms the high-dimensional input image into a compact code, capturing the essence of the image in a reduced form. The architecture of the encoder can vary depending on the type of autoencoder and the complexity of the data.
Latent Representation
The compressed representation generated by the encoder is known as the latent representation or code. This representation captures the essential features of the input image in a lower-dimensional space.
The dimensionality of the latent space is typically much smaller than the dimensionality of the input image, forcing the autoencoder to learn a concise and efficient representation. The latent representation serves as a bottleneck, compelling the autoencoder to extract the most salient features of the input.
Decoding
The latent representation is then passed through the decoder, another neural network responsible for reconstructing the image from the compressed representation. The decoder attempts to generate an output image that is as close as possible to the original input image, effectively reversing the encoding process.
The decoder's architecture mirrors the encoder's structure, allowing it to expand the compressed representation back to the original dimensions.
Output Image
The final step yields the output image, which is the reconstructed version of the input image generated by the decoder. The difference between the input and output images, known as the reconstruction error, serves as a critical metric for training the autoencoder.
By minimizing this error, the autoencoder learns to effectively capture and reconstruct the essential features of the input data. The reconstruction error is used to adjust the weights of the encoder and decoder networks during training.
How Autoencoders Work in Computer Vision

In computer vision, autoencoders play a crucial role in learning compressed representations of images that capture the essential features that define visual information. In this process, the autoencoder is trained to minimize the difference between the original image and the reconstructed image, forcing the network to learn a compact and efficient representation.
During training, the encoder learns to extract the most salient features from the input image, while the decoder learns to reconstruct the image from these features. This intricate interplay between the encoder and decoder enables the autoencoder to capture the underlying structure of the image, effectively learning a compressed representation that preserves the essential visual information. This capability makes autoencoders valuable tools for various computer vision tasks, such as image denoising, generation, and classification.
The Types of Autoencoders for Computer Vision
Several types of autoencoders have been developed, each with its own unique characteristics and applications:
Under complete Autoencoders
Undercomplete autoencoders are characterized by a latent space dimension that is smaller than the input dimension. This architectural constraint forces the network to learn a compressed representation of the data, effectively capturing the most salient features.
This compression makes them particularly useful for dimensionality reduction and feature extraction, where the goal is to represent the input data with fewer dimensions while preserving essential information. By learning a compact representation, undercomplete autoencoders can improve computational efficiency and reduce storage requirements.
Denoising Autoencoders
Denoising autoencoders are designed to reconstruct the original input from a corrupted version, adding robustness to the learning process. By training the network to remove noise or distortions, denoising autoencoders learn to identify and extract robust features that are invariant to these perturbations.
This makes them particularly effective for image denoising tasks, where the goal is to recover a clean image from a noisy observation. The added noise forces the autoencoder to learn more generalizable features, improving its performance on unseen data.
Sparse Autoencoders
Sparse autoencoders promote sparsity in the latent representation by constraining the activation of neurons in the latent layer. This sparsity constraint promotes the learning of more interpretable features because each neuron in the latent layer is specialized to represent specific aspects of the input data.
Sparsity is typically achieved by adding a regularization term to the loss function that penalizes non-zero activations in the latent layer. This encourages the network to activate only a small subset of neurons for each input, resulting in a more concise and interpretable representation.
Contrastive Autoencoders
Contrastive autoencoders learn representations that are invariant to small perturbations in the input data. They achieve this by using a contrastive loss function that encourages similar inputs to have similar representations and dissimilar inputs to have dissimilar representations.
This makes them robust to minor variations in the input, which is beneficial in various computer vision tasks where slight changes in the image should not significantly affect the representation.
Variational Autoencoders (VAE)
Variational autoencoders (VAEs) learn a probabilistic distribution over the latent space, allowing them to generate new images by sampling from this distribution. Unlike traditional autoencoders that learn a deterministic mapping, VAEs learn a probabilistic mapping, enabling them to generate diverse and realistic images.
They are widely used for image generation tasks and have shown promising results in generating novel and creative content.
Vector Quantized-Variational Autoencoder (VQ-VAE)
Vector Quantized-Variational Autoencoders (VQ-VAEs) combine the benefits of VAEs and vector quantization, leading to improved image generation quality and more structured latent representations.
By using a discrete latent space, VQ-VAEs achieve more efficient encoding and decoding, as well as generating higher-quality images. The discrete nature of the latent space allows for better control over the generated images and facilitates the learning of more structured representations.
Video Autoencoder
Video autoencoders are specifically designed to process video data, taking into account the temporal dependencies between frames. They learn to capture motion information and temporal dynamics within video sequences, making them suitable for tasks such as video prediction, compression, and anomaly detection.
By learning temporal relationships, video autoencoders can effectively model the evolution of visual information over time.
Masked Autoencoders (MAE)
Masked autoencoders (MAEs) are trained to reconstruct masked portions of an image, forcing them to learn a robust understanding of the image structure. By masking a significant portion of the input image and training the network to reconstruct the missing parts, MAEs learn to infer missing information and develop a comprehensive understanding of the image content. They have demonstrated impressive performance in self-supervised learning tasks, where labeled data is scarce.
Applications for Autoencoders in Computer Vision

Autoencoders have found numerous applications in computer vision, including:
Autoencoders in Anomaly Detection
Autoencoders can be effectively used for anomaly detection in images by identifying deviations from learned normal patterns. By training the autoencoder on a dataset of normal images, it learns to reconstruct these images with high fidelity. When presented with an anomalous image, the autoencoder will produce a higher reconstruction error, signaling a deviation from the learned normal patterns. This makes them particularly useful for detecting defects in manufacturing processes or identifying unusual medical images.
Autoencoders in Image Denoising
Denoising autoencoders excel at removing noise from images while preserving important details. By training on noisy images and learning to reconstruct a clean image, these autoencoders effectively filter out noise and enhance image quality. This capability is valuable in various applications, such as medical imaging and photography, where noise can obscure important details.
Autoencoders in Image Generation
Variational autoencoders (VAEs) are commonly employed for generating new images by sampling from the learned latent distribution. They are capable of creating realistic and diverse images, making them valuable tools for creative applications, such as generating artistic images or designing new product prototypes. The ability to generate new images from a learned distribution opens up exciting possibilities in the creative domain.
Autoencoders in Image Classification
Autoencoders can serve as effective feature extractors for image classification tasks. The learned latent representation, which captures the essential features of the input image, can be used as input to a classifier, improving classification accuracy.
By learning a compact and discriminative representation, autoencoders can enhance the performance of image classification models.
Autoencoders in Segmentation Tasks
Autoencoders can be adapted for segmentation tasks, where the goal is to partition an image into meaningful regions. They can learn to identify boundaries and segment objects within an image, which is essential in applications such as medical image analysis and autonomous driving.
By learning to differentiate between different regions within an image, autoencoders can facilitate accurate and efficient segmentation.
Applying Super-Resolution
Autoencoders are utilized to enhance the resolution of images, generating high-resolution images from low-resolution inputs. Super-Resolution applications are particularly useful for improving the quality of old or low-resolution images, enhancing detail,s and making them visually more appealing.
By learning the mapping between low-resolution and high-resolution images, autoencoders can effectively upscale images and improve their visual quality.
The Benefits of Autoencoders for Computer Vision
Autoencoders offer several advantages in computer vision applications:
Autoencoders Learn Features Automatically from the Input Data: A significant advantage of autoencoders is their ability to learn features directly from input data without requiring labeled examples. This unsupervised learning capability makes them particularly valuable in scenarios where labeled data is scarce, expensive to obtain, or simply unavailable.
By learning from the inherent structure of the data, autoencoders can extract meaningful features without explicit supervision, enabling their application in a wider range of scenarios.
Autoencoders Are Suitable for Learning More Robust Features that Generalize Better to New Data: Autoencoders are designed to learn robust features that generalize well to unseen data. This robustness stems from their ability to capture the underlying structure of the data, making them less susceptible to noise and variations in the input. This characteristic is particularly beneficial in real-world applications where data may be noisy, incomplete, or otherwise imperfect. By learning robust features, autoencoders can improve the reliability and performance of computer vision systems in challenging real-world scenarios.
Autoencoders Are Able to Learn More Complex and Abstract Features: Autoencoders possess the capability to learn complex and abstract features from data, going beyond simple surface-level representations. This ability to capture intricate patterns and relationships within the data is crucial for tasks that require a deeper understanding of the underlying information. By learning abstract representations, autoencoders can improve performance in various tasks, such as image classification and object recognition. This allows them to discern subtle differences and recognize complex patterns that might be missed by simpler methods.
The Limitations of Autoencoders for Computer Vision
Despite their advantages, autoencoders also have limitations:
Autoencoders Can Be Computationally Expensive
Training deep autoencoders, especially with complex architectures and large datasets, can be computationally intensive. The process of encoding and decoding data through multiple layers requires significant computational resources, which can be a limiting factor for some applications. The computational cost can be particularly challenging when dealing with high-resolution images or large video datasets.
Autoencoders May Be Prone to Overfitting
Like other deep learning models, autoencoders can be prone to overfitting, particularly when trained on limited data or with overly complex architectures. Overfitting occurs when the autoencoder learns to memorize the training data instead of generalizing to unseen data, resulting in poor performance on new examples. Techniques like regularization, dropout, and data augmentation can help mitigate overfitting and improve the generalization ability of the autoencoder.
Future and Outlook
The future of autoencoders in computer vision is promising. Ongoing research is focused on developing more efficient and powerful autoencoder architectures, exploring new applications, and addressing existing limitations. Areas of active research include:
Developing more efficient training algorithms for autoencoders is a key area of research. This includes exploring new optimization techniques and developing specialized hardware to accelerate the training process. More efficient training algorithms will enable the development of more complex and powerful autoencoders, pushing the boundaries of what is possible in computer vision.
Exploring new applications of autoencoders in areas such as 3D reconstruction, video analysis, and medical imaging is another promising direction. Autoencoders have the potential to revolutionize these fields by enabling the efficient processing and analysis of complex visual data. As research progresses, we can expect to see autoencoders playing an increasingly important role in these and other emerging areas.
Integrating autoencoders with other deep learning models, such as convolutional neural networks (CNNs) and recurrent neural networks (RNNs), is another avenue of exploration. By combining the strengths of different models, researchers aim to create more powerful and versatile systems for computer vision tasks. Integration with other models can enhance the performance and capabilities of autoencoders in various applications.
Developing autoencoders that can learn from limited data is a crucial challenge that researchers are actively addressing. This is particularly important in domains where large labeled datasets are not readily available. By developing techniques that enable autoencoders to learn effectively from small datasets, researchers aim to broaden their applicability to a wider range of real-world scenarios.
Conclusion
Autoencoders have become essential tools in computer vision, providing a powerful and versatile approach to unsupervised learning and feature extraction. Their ability to learn compressed representations of images has revolutionized applications ranging from anomaly detection and image denoising to image generation and super-resolution.
While challenges such as computational complexity and potential overfitting remain, ongoing research and development efforts are actively addressing these limitations and paving the way for even more powerful and efficient autoencoder architectures. As the field of computer vision continues to advance, autoencoders will play an increasingly important role in shaping the future of image processing, analysis, and understanding. Their ability to learn complex patterns and relationships from visual data makes them indispensable tools for addressing the ever-growing challenges in this dynamic field.
Note: Some visuals on this blog post were generated using AI tools.