Evolution of the Object Detection Pipeline
Mar 28, 2026
Written by: Maryam Rajaei
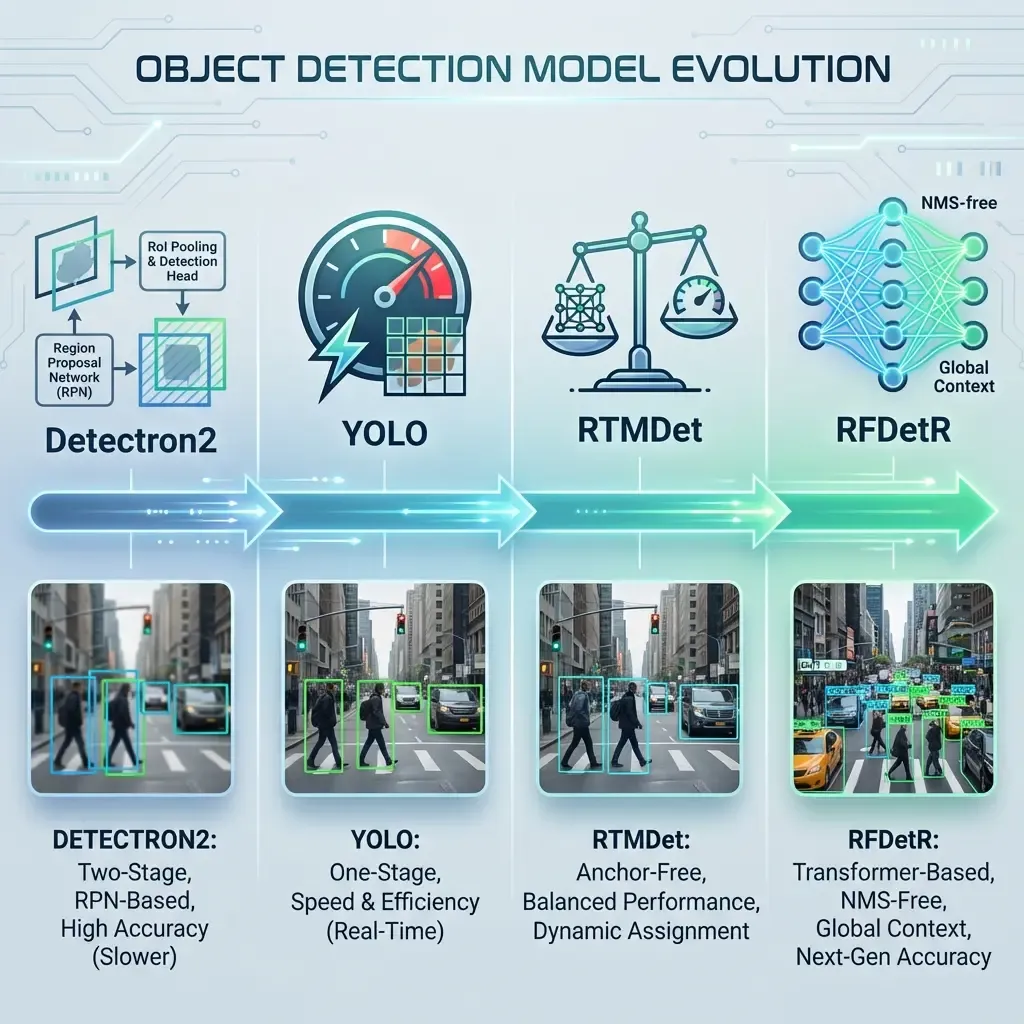
1. The Starting Point: Detectron2
Initially, our pipeline relied on Detectron2, Facebook AI Research’s (FAIR) powerhouse. It provided a robust library for Faster R-CNN and Mask R-CNN.
- Advantages: High flexibility, excellent documentation, and high-quality results for instance segmentation.
- The Bottleneck: Detectron2 is primarily built on top of the R-CNN family, which are "two-stage" detectors. This made them computationally expensive and difficult to deploy for real-time applications without high-end GPU clusters.

2. Transition to the YOLO Family
To address the latency issues, we moved toward the YOLO (You Only Look Once) ecosystem.
- Improvement: YOLO introduced a "one-stage" detection paradigm. By eliminating the Region Proposal Network (RPN), we achieved significantly higher frames per second (FPS).
- The Bottleneck: While fast, YOLO models (specifically earlier versions) often struggled with small object detection and localization precision compared to two-stage detectors. Furthermore, the reliance on fixed "Anchors" made them less adaptable to diverse object scales without manual tuning.

3. Refining with RTMDet (Real-Time Models)
Seeking a middle ground between YOLO's speed and R-CNN's accuracy, we adopted RTMDet.
- Improvement: RTMDet introduced an anchor-free design and a more efficient backbone. It significantly reduced the gap between real-time performance and high-precision detection.
- The Remaining Gap: Despite its efficiency, RTMDet still relies on Non-Maximum Suppression (NMS). NMS is a post-processing step that can become a bottleneck and often leads to issues in crowded scenes where bounding boxes overlap heavily.

4. The Final Leap: RFDetR (Transformer-based Detection)
Our current standard, RFDetR, represents a fundamental shift from Convolutional Neural Networks (CNNs) to Transformers.
- How it solves previous issues:
- End-to-End Excellence: RFDetR is an NMS-free model. It treats detection as a set-prediction problem, removing the need for hand-crafted post-processing components.
- Global Context: Unlike YOLO or RTMDet, which look at local pixels, the Transformer architecture uses Self-Attention to understand the relationship between all parts of the image simultaneously.
- Superior Accuracy: By leveraging the RFDetR (Recurrent/Refined DEtection TRansformer) architecture, we achieved higher Mean Average Precision (mAP) while maintaining competitive inference speeds.

Summary Table of Evolution
| Model | Architecture Type | Main Strength | Primary Weakness |
|---|---|---|---|
| Detectron2 | Two-Stage (CNN) | High Accuracy | Very Slow (Inference) |
| YOLO Family | One-Stage (CNN) | Real-time Speed | Small Object Sensitivity |
| RTMDet | Anchor-free (CNN) | Optimized Balance | Still relies on NMS |
| RFDetR | Transformer-based | Global Context / NMS-free | Requires more training data |
Share:
Follow us for the latest updates
Table of Contents
No headings were found on this page.