Evolution of Segmentation Models in Our Computer Vision Pipeline
Mar 31, 2026
Written by: Maryam Rajaei
Over time, the segmentation models used in our computer vision projects evolved as the requirements of different applications increased. Early solutions prioritized stability and ease of training, while later models focused more on efficiency, scalability, and improved performance on complex scenes. The transition from SegDECNet to RTMDet and eventually to SegFormer reflects this progression.
SegDecNet
SegDecNet was among the earlier models used for segmentation tasks. It is based on a convolutional neural network architecture designed for reliable pixel‑level predictions. SegDecNet follows a fully convolutional encoder–decoder architecture. The encoder extracts hierarchical spatial features using stacked convolutional layers, while the decoder progressively upsamples these features to produce dense pixel‑level segmentation maps. This design focuses on stable feature extraction and reconstruction without relying on attention mechanisms.
Advantages
- Stable training and relatively simple architecture.
- Works well with moderate dataset sizes.
- Efficient in terms of computational requirements compared to transformer‑based approaches.
- Reliable performance on structured visual patterns and relatively controlled environments.
Limitations
- Limited ability to capture long‑range spatial dependencies.
- Performance decreases when scenes become more complex or contain large variations.
- Less flexible compared to more recent architectures designed for multi-scale reasoning.
Typical Usage
SegDecNet was suitable for projects where datasets were moderate in size and visual structures were relatively consistent. It provided a dependable baseline for semantic segmentation tasks.

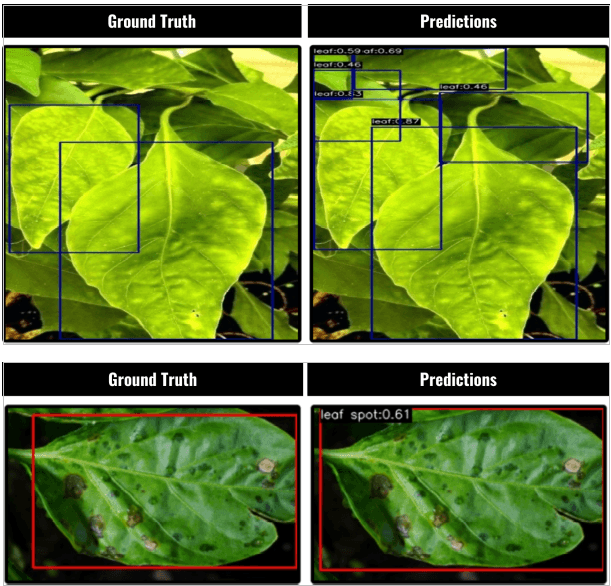
RTMDet (Segmentation Variant)
As project requirements expanded to include faster inference and more complex scenes, RTMDet was introduced. Although primarily designed as an object detection framework, its segmentation variants support instance-level segmentation. RTMDet is an anchor‑free detection architecture that uses a convolutional backbone with a feature pyramid network (FPN) to extract multi‑scale features. For segmentation variants, a mask prediction branch is added on top of detection features, enabling instance-level segmentation by generating object masks alongside bounding box predictions.
Advantages
- Optimized for high inference speed and real‑time applications.
- Strong multi-scale feature extraction, improving detection and segmentation performance.
- Suitable for instance segmentation scenarios where objects must be separated individually.
- More flexible for pipelines combining detection and segmentation.
Limitations
- Fine boundary precision can sometimes be limited compared to specialized segmentation architectures.
- Requires more careful tuning to achieve optimal results.
Typical Usage
RTMDet became useful for applications requiring faster processing or instance-level segmentation, particularly in scenarios where object detection and segmentation were needed together.
SegFormer
With increasing demands for higher segmentation accuracy and better handling of complex scenes, SegFormer was adopted. It is a transformer-based semantic segmentation architecture designed to capture both local and global context effectively. SegFormer combines a hierarchical Vision Transformer encoder with a lightweight MLP-based decoder. The encoder uses efficient self‑attention to model long‑range spatial relationships while producing multi‑scale feature maps, and the decoder fuses these features to generate high‑resolution semantic segmentation outputs.
Advantages
- Strong ability to model global spatial relationships using transformer attention.
- High segmentation accuracy in complex and diverse environments.
- Robust performance across different object scales and scene structures.
- Lightweight decoder design improves efficiency compared to many transformer-based models.
Limitations
- Higher training cost compared to CNN-based approaches.
- Requires more computational resources, especially for larger model variants.
Typical Usage
SegFormer is particularly effective for semantic segmentation tasks involving complex scenes, diverse object structures, and datasets with high variability. It is well suited for applications where segmentation accuracy is a primary requirement.

Summary
The progression from SegDECNet to RTMDet and later to SegFormer reflects the growing needs of various computer vision projects. Initial models focused on stability and simplicity, while later architectures introduced improved speed, scalability, and contextual understanding. This gradual transition allowed the adoption of more capable models as project complexity and performance requirements increased.
Follow us for the latest updates
Table of Contents
No headings were found on this page.